
Internal table secondary indexes

This is how internal tables used to be declared:
DATA: itbl TYPE TABLE OF bkpf.And then you’d SELECT, SORT and always try to use BINARY SEARCH with READ TABLE. Since LOOP doesn’t support BINARY SEARCH… using LOOP WHERE was not fast at all.
Back then all internal tables were called ITBL.
Then SAP started supporting what it calls “fully specified internal table” which are internal tables with properly declared key and a specific internal organization and index access mode:
DATA: t_bkpf TYPE SORTED TABLE OF bkpf WITH UNIQUE KEY bukrs belnr gjahr.These tables no longer need to SORT nor BINARY SEARCH because the index is automatically used to access the data. And LOOPS also benefit from it.
Thus far, nothing new (although for some strange reason I keep running into new code still using tables not fully specified. Fortunately it’s been a while since I last saw one called ITBL).
But what you may not yet know is that internal tables now supports secondary indexes:
DATA: t_bkpf TYPE SORTED TABLE OF bkpf
WITH UNIQUE KEY bukrs belnr gjahr
WITH NON-UNIQUE SORTED KEY key_budat COMPONENTS budat.This solves those situations in which the same program has to access an internal table in more than one way.
And to showcase the virtues of secondary indexes I wrote a program comparing the old BINARY SEARCH with a brand new table with secondary indexes.
You can find it here in GitHub.
And here are the results (database data load time is not included in the final score):
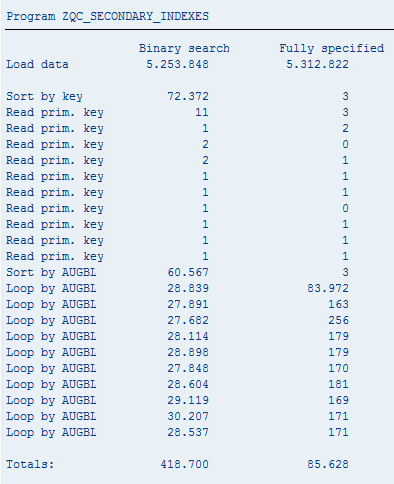
It’s not hard to decide which is the best approach, right?
Thanks redspotted for the photo.
Greetings from Abapinho.