
Índices secundários em tabelas internas

Durante anos as tabelas internas eram declaradas assim:
DATA: itbl TYPE TABLE OF bkpf.E depois era fazer SELECT, SORT e tentar usar sempre BINARY SEARCH no READ TABLE. Como o LOOP não permite BINARY SEARCH… usar WHERE com LOOPs não era nada rápido.
Nesta altura as tabelas internas ainda se chamavam todas ITBL.
Entretanto a SAP passou a permitir fazer aquilo que eles chamam de “fully specified internal table”, ou seja, declarar chaves de tabelas internas e a escolher o tipo de organização e índices destas:
DATA: t_bkpf TYPE SORTED TABLE OF bkpf WITH UNIQUE KEY bukrs belnr gjahr.Com tabelas assim definidas já não é preciso fazer SORT nem usar o BINARY SEARCH porque os índices que definimos são automaticamente usados tanto no READ TABLE como no LOOP, que assim passa a ser rápido.
Até aqui acho que não revelei nada de novo (ainda que, surpreendentemente, vou vendo muito preguiçoso que continua a não declarar a chave nas tabelas internas. Ao menos já lá vai algum tempo desde a última vez que vi uma chamada ITBL).
Mas o que pouca gente sabe é que recentemente a SAP passou a permitir criar índices secundários nas tabelas internas:
DATA: t_bkpf TYPE SORTED TABLE OF bkpf
WITH UNIQUE KEY bukrs belnr gjahr
WITH NON-UNIQUE SORTED KEY key_budat COMPONENTS budat.Isto resolve as situações em que temos de aceder aos dados de uma tabela interna de mais do que uma forma no mesmo programa.
E para mostrar as virtudes dos índices secundários escrevi um programa que compara uma tabela das velhas acedida com BINARY SEARCH com uma tabela das novinhas com dois índices.
O programa está aqui no GitHub.
Eis os resultados (o tempo de carregamento não está contabilizado no resultado final, apenas os acessos):
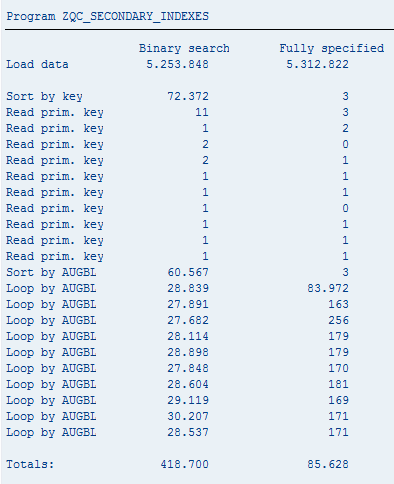
É fácil concluir qual é a melhor abordagem.
Obrigado redspotted pela foto.
O Abapinho saúda-vos.